前言
近年来,机器学习人工智能领域大热,本文也来蹭蹭热点,接下来将为大家理清机器学习相关概念,介绍机器学习的主要方法
机器学习概念
什么是机器学习
我们通常在计算机编程的时候,都是已知输入,然后通过一定的算法产生输出,如下图所示:
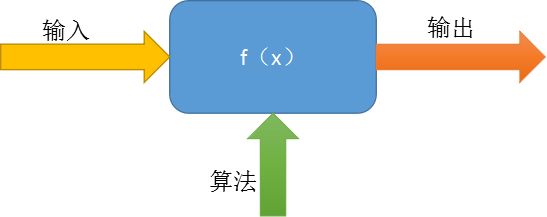
而还有一种情况呢,我们知道了输入和输出,但是却不知道中间的算法,这时候就需要用机器学习通过观察输入输出来学习这个算法,我们叫做知识,然后用学到的知识通过新的输入来产生输出。简而言之机器学习是用来寻找输入输出间的映射关系的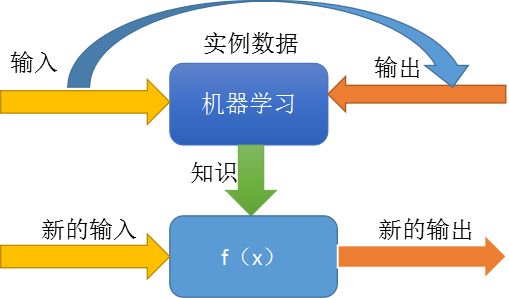
其实我们人在学习思考时,脑子里也有这么个映射过程,当我们看到猫的图片,在脑子里产生了映射,于是乎,就说出了猫这个词,所以呢机器学习就是让计算机和人一样思考

机器学习相关概念的区别
在谈到机器学习时,我们经常会听到下面几个概念:数据挖掘,人工智能等等,那他们之间有什么联系呢?我们先来看看下面的这幅图:
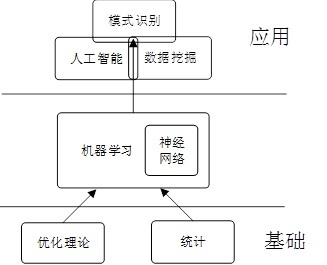
也就是说机器学习是数据挖掘它们的底层,机器学习给它们提供算法,数据挖掘则是机器学习的应用。
机器学习的应用
像我们熟知的Apple的faceID,google的AlphaGo,MicroSoft的小娜都是机器学习的典型应用
机器学习方法
实现机器学习有多种方法,这里方法是我们通常所说的算法,主要有下面几种:
监督学习方法
所谓监督学习方法就是说随便给一堆数据和数据对应的标签,计算机在学习之后能根据新的输入数据判断它们对应的标签。
举个例子,我们给计算机一大堆猫狗的图片,并告诉它,哪些是狗,哪些是猫,计算机学习之后,再给它看猫和狗的图片,它就能告诉我们哪些是狗,哪些是猫。
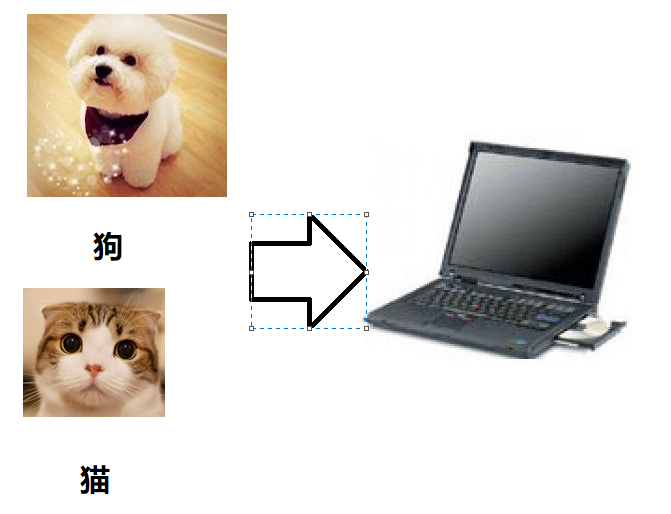

监督学习方法用于分类和回归,我们熟知的神经网络就是一种监督学习方法。
非监督学习方法
我们有的时候只给计算机数据,不给计算机对应的标签,计算机能通过观察数据之间的规率进行数据归类
还是上面的例子,我们这次不告诉计算机哪些是狗,哪些是猫,计算机学习之后能把他们归类出来。
非监督学习用于聚类,如k-means算法
半监督学习方法
半监督学习方法综合了监督学习和非监督学习两种方法。在初始阶段给计算机一些有标签的数据和大量没有标签的数据,计算机学习后能进行归类
半监督学习用于训练更高效更准确的模型,因为它既避免了带标签的数据少而的模型过拟合,也减少了打标签的工作量。
强化学习
强化学习是学习一个最优策略,可以让本体在特定环境中,根据当前的状态,做出行动,从而获得最大奖励。
来个新例子,这次,我们让计算机打篮球,我们并不需要告诉计算机怎么打篮球,我们只需要给它个篮球,让它自己打,然后我们对计算机打分,进球分越高,打分越高,这里的打分就是上面的奖励,每次计算机要做的就是获得最大奖励,一开始,面对陌生的环境,计算机并不知道怎么进球,经过奖励刺激后,命中率就会越来越高。
google的AlphaZero便是强化学习的典型应用
遗传算法
模拟自然界优胜劣汰的进化现象,把搜索空间(问题解的组成空间)映射为遗传空间,把可能的解编码成一个向量——染色体,向量的每个元素称为基因。通过不断计算各染色体的适应值,选择最好的染色体,获得最优解。
还是拿上面的例子来说,先训练出两个打篮球的计算机ai,让这两个aic重组,变异产生后代种群,挑出最会打篮球的再进行重组变异,如此循环,每次挑出最强的
